Translator usando Transformer
In this project i practically implemented the Transformer architecture to translate the Portugese Language to English language.


Requirements
This project requires these corresponding requirements. First create a virtual environment (VENV) of python version 3.10/3.11/3.9 . After creating the virtual environment install these requirements Requirements. In this link i provided the requirements file. After installing these requirements, Use this code install all requirements. In final step, You must bring a coffee .
python3.10 -m venv venv
venv\Scripts\activate
pip install -r requirements.txt

Before u start implementing this code snippet i prefer you to visit, a well explained blog by Kaushik. And if you are front bencher then try to understand the theory from Attention is all u need paper and a well explained blog by Jay Alammar.
I GUESS YOU FINISHED YOUR COFFEE☕LET’S GET START IT

First you need to import all the required packages for this project.
import tensorflow_datasets as tfds
import tensorflow as tf
import time
import numpy as np
import matplotlib.pyplot as plt
I took the language dataset from tensorflow dataset (TFDS). Here i am downloading the dataset locally.
examples, metadata = tfds.load('ted_hrlr_translate/pt_to_en', with_info=True,
as_supervised=True)
train_examples, val_examples = examples['train'], examples['validation']
Now , I need to tokenize the dataset. Well tokenize is the crucial state in NLP process. Where the text data is formatted to another format which is computable for machine. If u want to read about tokenization, Read This..
tokenizer_en = tfds.deprecated.text.SubwordTextEncoder.build_from_corpus(
(en.numpy() for pt, en in train_examples), target_vocab_size=2**13)
tokenizer_pt = tfds.deprecated.text.SubwordTextEncoder.build_from_corpus(
(pt.numpy() for pt, en in train_examples), target_vocab_size=2**13)
sample_string = 'Transformer is awesome.'
tokenized_string = tokenizer_en.encode(sample_string)
print ('Tokenized string is {}'.format(tokenized_string))
original_string = tokenizer_en.decode(tokenized_string)
print ('The original string: {}'.format(original_string))
assert original_string == sample_string
Here below, there were several functions which represents the encoding , positional encoding and other important sub function that required in further steps.
def encode(lang1, lang2):
lang1 = [tokenizer_pt.vocab_size] + tokenizer_pt.encode(
lang1.numpy()) + [tokenizer_pt.vocab_size+1]
lang2 = [tokenizer_en.vocab_size] + tokenizer_en.encode(
lang2.numpy()) + [tokenizer_en.vocab_size+1]
return lang1, lang2
def filter_max_length(x, y, max_length=MAX_LENGTH):
return tf.logical_and(tf.size(x) <= max_length,
tf.size(y) <= max_length)
def tf_encode(pt, en):
result_pt, result_en = tf.py_function(encode, [pt, en], [tf.int64, tf.int64])
result_pt.set_shape([None])
result_en.set_shape([None])
return result_pt, result_en
def tf_encode(pt, en):
result_pt, result_en = tf.py_function(encode, [pt, en], [tf.int64, tf.int64])
result_pt.set_shape([None])
result_en.set_shape([None])
return result_pt, result_en
def create_padding_mask(seq):
seq = tf.cast(tf.math.equal(seq, 0), tf.float32)
return seq[:, tf.newaxis, tf.newaxis, :] # (batch_size, 1, 1, seq_len)
def create_look_ahead_mask(size):
mask = 1 - tf.linalg.band_part(tf.ones((size, size)), -1, 0)
return mask # (seq_len, seq_len)
Before going to step, u need to read theory regarding transformer i.e attention and it’s types. Here is the theory behind self attention mechanism.
Self-Attention Mechanism (Scaled Dot-Product Attention)
Helps the model focus on relevant words in a sentence, regardless of their position.
Computes attention scores between all words in an input sequence.
Uses Query (Q), Key (K), and Value (V) matrices to determine word importance.
Formula:

def scaled_dot_product_attention(q, k, v, mask):
matmul_qk = tf.matmul(q, k, transpose_b=True) # (..., seq_len_q, seq_len_k)
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
if mask is not None:
scaled_attention_logits += (mask * -1e9)
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1) # (..., seq_len_q, seq_len_k)
output = tf.matmul(attention_weights, v) # (..., seq_len_q, depth_v)
return output, attention_weights
combination of more than one attention forming a multihead attention layer. This is the base of a transformer during context extraction.
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
self.depth = d_model // self.num_heads
self.wq = tf.keras.layers.Dense(d_model)
self.wk = tf.keras.layers.Dense(d_model)
self.wv = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model)
def split_heads(self, x, batch_size):
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, v, k, q, mask):
batch_size = tf.shape(q)[0]
q = self.wq(q) # (batch_size, seq_len, d_model)
k = self.wk(k) # (batch_size, seq_len, d_model)
v = self.wv(v) # (batch_size, seq_len, d_model)
q = self.split_heads(q, batch_size) # (batch_size, num_heads, seq_len_q, depth)
k = self.split_heads(k, batch_size) # (batch_size, num_heads, seq_len_k, depth)
v = self.split_heads(v, batch_size) # (batch_size, num_heads, seq_len_v, depth)
# scaled_attention.shape == (batch_size, num_heads, seq_len_q, depth)
# attention_weights.shape == (batch_size, num_heads, seq_len_q, seq_len_k)
scaled_attention, attention_weights = scaled_dot_product_attention(
q, k, v, mask)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3]) # (batch_size, seq_len_q, num_heads, depth)
concat_attention = tf.reshape(scaled_attention,
(batch_size, -1, self.d_model)) # (batch_size, seq_len_q, d_model)
output = self.dense(concat_attention) # (batch_size, seq_len_q, d_model)
return output, attention_weights
Sorry to interrupt your coding flow, It’s time to watch the encoder and decoder layer architecture. Now i am writing a snipper for the encoding layer and decoding layer.
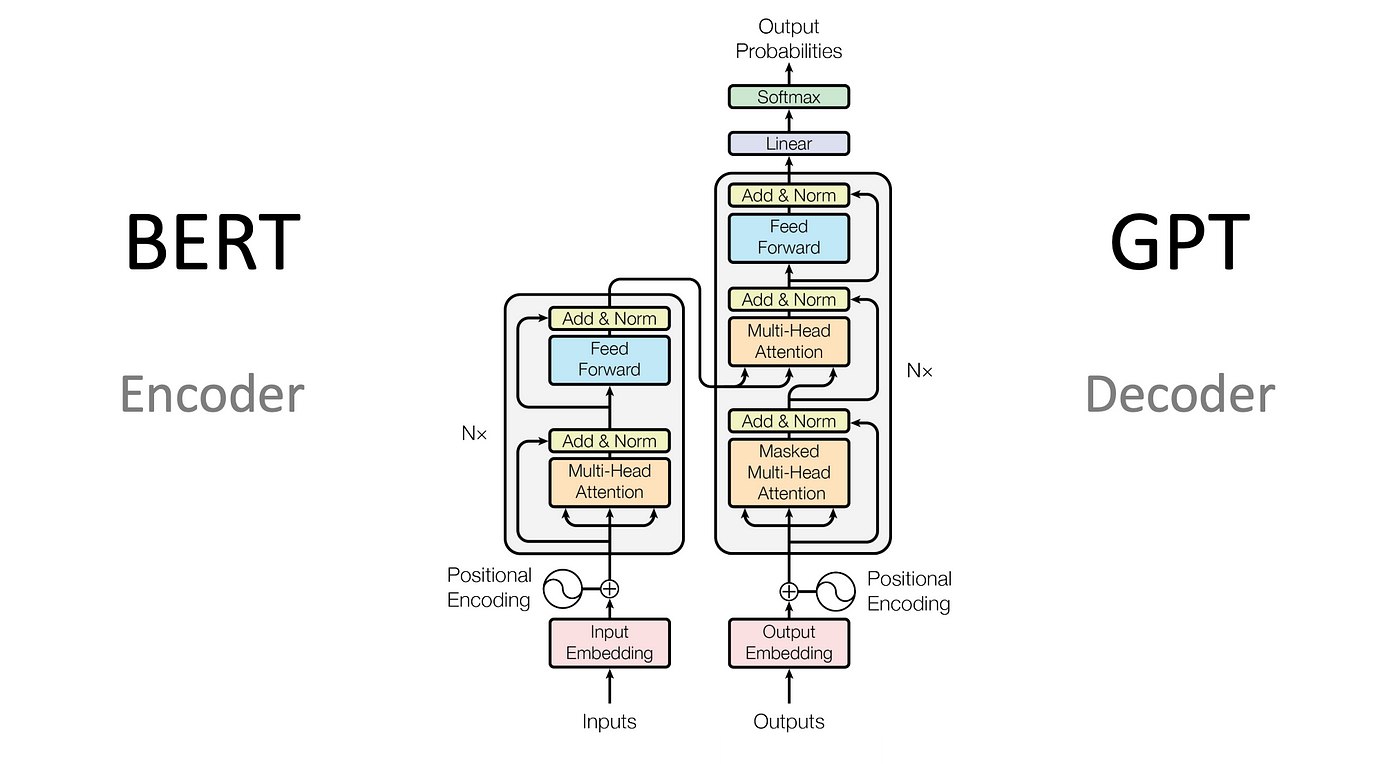
class EncoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(EncoderLayer, self).__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
def call(self, x, training, mask):
attn_output, _ = self.mha(x, x, x, mask) # (batch_size, input_seq_len, d_model)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(x + attn_output) # (batch_size, input_seq_len, d_model)
ffn_output = self.ffn(out1) # (batch_size, input_seq_len, d_model)
ffn_output = self.dropout2(ffn_output, training=training)
out2 = self.layernorm2(out1 + ffn_output) # (batch_size, input_seq_len, d_model)
return out2
Code for the decoder layer :
class DecoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(DecoderLayer, self).__init__()
self.mha1 = MultiHeadAttention(d_model, num_heads)
self.mha2 = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm3 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
self.dropout3 = tf.keras.layers.Dropout(rate)
def call(self, x, enc_output, training,
look_ahead_mask, padding_mask):
# enc_output.shape == (batch_size, input_seq_len, d_model)
attn1, attn_weights_block1 = self.mha1(x, x, x, look_ahead_mask) # (batch_size, target_seq_len, d_model)
attn1 = self.dropout1(attn1, training=training)
out1 = self.layernorm1(attn1 + x)
attn2, attn_weights_block2 = self.mha2(
enc_output, enc_output, out1, padding_mask) # (batch_size, target_seq_len, d_model)
attn2 = self.dropout2(attn2, training=training)
out2 = self.layernorm2(attn2 + out1) # (batch_size, target_seq_len, d_model)
ffn_output = self.ffn(out2) # (batch_size, target_seq_len, d_model)
ffn_output = self.dropout3(ffn_output, training=training)
out3 = self.layernorm3(ffn_output + out2) # (batch_size, target_seq_len, d_model)
return out3, attn_weights_block1, attn_weights_block2
After building a single encoding layer and decoder layer , let’s combine all layer to form a network.
class Encoder(tf.keras.layers.Layer):
def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size,
maximum_position_encoding, rate=0.1):
super(Encoder, self).__init__()
self.d_model = d_model
self.num_layers = num_layers
self.embedding = tf.keras.layers.Embedding(input_vocab_size, d_model)
self.pos_encoding = positional_encoding(maximum_position_encoding,
self.d_model)
self.enc_layers = [EncoderLayer(d_model, num_heads, dff, rate)
for _ in range(num_layers)]
self.dropout = tf.keras.layers.Dropout(rate)
def call(self, x, training, mask):
seq_len = tf.shape(x)[1]
x = self.embedding(x) # (batch_size, input_seq_len, d_model)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x, training=training)
for i in range(self.num_layers):
x = self.enc_layers[i](x, training=training, mask=mask)
return x # (batch_size, input_seq_len, d_model)
class Decoder(tf.keras.layers.Layer):
def __init__(self, num_layers, d_model, num_heads, dff, target_vocab_size,
maximum_position_encoding, rate=0.1):
super(Decoder, self).__init__()
self.d_model = d_model
self.num_layers = num_layers
self.embedding = tf.keras.layers.Embedding(target_vocab_size, d_model)
self.pos_encoding = positional_encoding(maximum_position_encoding, d_model)
self.dec_layers = [DecoderLayer(d_model, num_heads, dff, rate)
for _ in range(num_layers)]
self.dropout = tf.keras.layers.Dropout(rate)
def call(self, x, enc_output, training,
look_ahead_mask, padding_mask):
seq_len = tf.shape(x)[1]
attention_weights = {}
x = self.embedding(x) # (batch_size, target_seq_len, d_model)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x, training=training)
for i in range(self.num_layers):
x, block1, block2 = self.dec_layers[i](x, enc_output=enc_output, training=training,
look_ahead_mask=look_ahead_mask, padding_mask=padding_mask)
attention_weights['decoder_layer{}_block1'.format(i+1)] = block1
attention_weights['decoder_layer{}_block2'.format(i+1)] = block2
# x.shape == (batch_size, target_seq_len, d_model)
return x, attention_weights
Building the Transformer
class Transformer(tf.keras.Model):
def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size,
target_vocab_size, pe_input, pe_target, rate=0.1):
super(Transformer, self).__init__()
self.encoder = Encoder(num_layers, d_model, num_heads, dff,
input_vocab_size, pe_input, rate)
self.decoder = Decoder(num_layers, d_model, num_heads, dff,
target_vocab_size, pe_target, rate)
self.final_layer = tf.keras.layers.Dense(target_vocab_size)
def call(self, inp, tar, training, enc_padding_mask,
look_ahead_mask, dec_padding_mask):
enc_output = self.encoder(x=inp, training=training, mask=enc_padding_mask)
# dec_output.shape == (batch_size, tar_seq_len, d_model)
dec_output, attention_weights = self.decoder(
x=tar, enc_output=enc_output, training=training,
look_ahead_mask=look_ahead_mask, padding_mask=dec_padding_mask)
# Change this line to pass dec_output as a positional argument
final_output = self.final_layer(dec_output)
return final_output, attention_weights
After init the Transformer , let’s build a transformers with all the required parameters. Generate random input and target tensors and Call the transformer with the appropriate arguments.
sample_transformer = Transformer(
num_layers=2,
d_model=512,
num_heads=8,
dff=2048,
input_vocab_size=8500,
target_vocab_size=8000,
pe_input=10000, pe_target=6000
)
# Generate random input and target tensors
temp_input = tf.random.uniform((64, 62), minval=0, maxval=8000, dtype=tf.int64)
temp_target = tf.random.uniform((64, 26), minval=0, maxval=8000, dtype=tf.int64)
# Call the transformer with the appropriate arguments
fn_out, _ = sample_transformer(inp=temp_input, tar=temp_target, # Changed inputs and target to inp and tar
training=False,
enc_padding_mask=None,
look_ahead_mask=None,
dec_padding_mask=None)
fn_out.shape # (batch_size, tar_seq_len, target_vocab_size)
After this step, Let’s create a loss function. Using this ,we can proceed with our further step. This function calculates a loss while ignoring padding values in sequence-based models. It first creates a mask that identifies non-padding positions by checking where the true target values (real) are not equal to zero. A predefined loss function (loss_object) is then applied to compute the loss between the true and predicted values. The mask is cast to the same data type as the loss and multiplied element-wise to set padding losses to zero. Finally, the function returns the mean loss across the batch, ensuring that only meaningful tokens contribute to the loss calculation.
def loss_function(real, pred):
mask = tf.math.logical_not(tf.math.equal(real, 0))
loss_ = loss_object(real, pred)
mask = tf.cast(mask, dtype=loss_.dtype)
loss_ *= mask
return tf.reduce_mean(loss_)
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(
name='train_accuracy')
This code implements the training loop for a Transformer model in TensorFlow using the @tf.function decorator for efficient execution. The train_step function processes a batch of input (inp) and target (tar) sequences by applying masking, computing predictions, and updating model parameters via backpropagation.
The target sequence is split into tar_inp (input to the decoder) and tar_real (the expected output). Masks are generated using create_masks to handle padding and prevent the model from attending to future tokens. The loss is calculated using loss_function, and gradients are computed using tf.GradientTape(). These gradients are then applied to update the model parameters via optimizer.apply_gradients().
Two metrics, train_loss and train_accuracy, track the model's performance. The training loop iterates through EPOCHS, resetting these metrics at the start of each epoch. After every batch, it prints loss and accuracy statistics. Every five epochs, a checkpoint is saved using ckpt_manager.save(). Finally, the total time taken for the epoch is printed.
@tf.function(input_signature=train_step_signature)
def train_step(inp, tar):
tar_inp = tar[:, :-1]
tar_real = tar[:, 1:]
enc_padding_mask, combined_mask, dec_padding_mask = create_masks(inp, tar_inp)
with tf.GradientTape() as tape:
predictions, _ = transformer(inp=inp, tar=tar_inp,
training=True,
enc_padding_mask=enc_padding_mask,
look_ahead_mask=combined_mask,
dec_padding_mask=dec_padding_mask)
loss = loss_function(tar_real, predictions)
gradients = tape.gradient(loss, transformer.trainable_variables)
optimizer.apply_gradients(zip(gradients, transformer.trainable_variables))
# Update the metrics' states
train_loss.update_state(loss)
train_accuracy.update_state(tar_real, predictions)
# ... (previous code remains the same)
# Define train_loss and train_accuracy outside the loop
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
for epoch in range(EPOCHS):
start = time.time()
# Reset the metrics' states at the beginning of each epoch
train_loss.reset_state()
train_accuracy.reset_state()
# inp -> portuguese, tar -> english
for (batch, (inp, tar)) in enumerate(train_dataset):
train_step(inp=inp, tar=tar) # Call train_step to update the metrics
if batch % 50 == 0:
print('Epoch {} Batch {} Loss {:.4f} Accuracy {:.4f}'.format(
epoch + 1, batch, train_loss.result(), train_accuracy.result()))
if (epoch + 1) % 5 == 0:
ckpt_save_path = ckpt_manager.save()
print('Saving checkpoint for epoch {} at {}'.format(epoch + 1,
ckpt_save_path))
print('Epoch {} Loss {:.4f} Accuracy {:.4f}'.format(epoch + 1,
train_loss.result(),
train_accuracy.result()))
print('Time taken for 1 epoch: {} secs\n'.format(time.time() - start))
This function evaluates an input sentence by generating a translated output using a trained Transformer model through an autoregressive decoding approach. It first tokenizes the input sentence, adding start and end tokens, and expands its dimensions to match the expected input shape. The decoder is initialized with a start token, and an empty output sequence is prepared. A loop runs for up to MAX_LENGTH iterations, where necessary masks are computed and passed along with the encoder input and current decoder output to the Transformer model. The model generates predictions for the next token, which is then appended to the output sequence. If the predicted token is the end-of-sequence token, the process stops and returns the generated sentence along with attention weights. This function enables sequence generation, commonly used in tasks like machine translation, where each token is predicted based on both the input sentence and previously generated tokens.
def evaluate(inp_sentence):
start_token = [tokenizer_pt.vocab_size]
end_token = [tokenizer_pt.vocab_size + 1]
inp_sentence = start_token + tokenizer_pt.encode(inp_sentence) + end_token
encoder_input = tf.expand_dims(inp_sentence, 0)
decoder_input = [tokenizer_en.vocab_size]
output = tf.expand_dims(decoder_input, 0)
for i in range(MAX_LENGTH):
enc_padding_mask, combined_mask, dec_padding_mask = create_masks(
encoder_input, output)
# predictions.shape == (batch_size, seq_len, vocab_size)
# Pass all required arguments to the transformer call
predictions, attention_weights = transformer(inp=encoder_input, # Changed encoder_input to inp
tar=output, # Changed output to tar
training=False,
enc_padding_mask=enc_padding_mask,
look_ahead_mask=combined_mask, # Added look_ahead_mask
dec_padding_mask=dec_padding_mask)
predictions = predictions[: ,-1:, :] # (batch_size, 1, vocab_size)
predicted_id = tf.cast(tf.argmax(predictions, axis=-1), tf.int32)
if predicted_id == tokenizer_en.vocab_size+1:
return tf.squeeze(output, axis=0), attention_weights
output = tf.concat([output, predicted_id], axis=-1)
return tf.squeeze(output, axis=0), attention_weights
The translate function takes an input sentence and generates a translated output using a trained Transformer model. It first calls the evaluate function to obtain the predicted token sequence and attention weights. The predicted sequence is then decoded into a human-readable sentence by filtering out special tokens and converting token indices back into words using tokenizer_en.decode(). The function prints both the input sentence and the predicted translation. If the optional plot parameter is provided, it visualizes the attention weights to analyze how the model aligns words between the input and output sequences. This function serves as a simple interface for testing and visualizing Transformer-based translations, making it useful for evaluating machine translation models.
def translate(sentence, plot=''):
result, attention_weights = evaluate(sentence)
predicted_sentence = tokenizer_en.decode([i for i in result
if i < tokenizer_en.vocab_size])
print('Input: {}'.format(sentence))
print('Predicted translation: {}'.format(predicted_sentence))
if plot:
plot_attention_weights(attention_weights, sentence, result, plot)
translate("este é um problema que temos que resolver.")
print ("Real translation: this is a problem we have to solve .")

Ahhhh…. Finally Completed…. Before u left …. Follow the final Step.
The final step is to follow me on Instagram, GitHub, LinkedIn, HashNode . And stay tuned for our next post and Special Thanks to 🌟 Kaushik Panigrahi.
